Ever wondered why your server crashes or your app slows down? A solid system monitor might be the missing piece. It’s not just about tracking CPU usage—it’s about gaining full control over your digital ecosystem.
What Is a System Monitor and Why It Matters

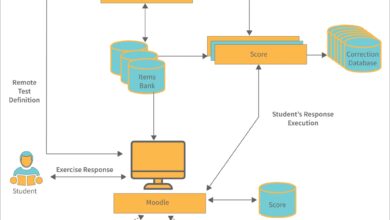
A system monitor is a software tool designed to track, analyze, and report the performance and health of computer systems, servers, networks, and applications. In today’s digital-first world, where downtime can cost thousands per minute, having real-time visibility into system operations is no longer optional—it’s essential.


Core Functions of a System Monitor
At its heart, a system monitor performs continuous observation of key system metrics. These include CPU load, memory usage, disk I/O, network bandwidth, and process activity. By collecting this data, it enables administrators to detect anomalies, predict failures, and optimize resource allocation.
- Real-time tracking of CPU, RAM, and disk usage
- Alerting mechanisms for threshold breaches
- Historical data logging for trend analysis
Types of System Monitoring
System monitoring isn’t a one-size-fits-all solution. Different environments require different approaches. For instance, network monitoring focuses on bandwidth and latency, while application monitoring zeroes in on response times and error rates.
- Hardware monitoring: Tracks physical components like servers and storage devices
- Software monitoring: Observes application performance and service availability
- Cloud monitoring: Extends visibility to virtualized and containerized environments
“Without monitoring, you’re flying blind. You won’t know when something breaks until users start complaining.” — DevOps Engineer, Google Cloud
Top 7 System Monitor Tools in 2024
Choosing the right system monitor can make or break your IT operations. Below is a curated list of the most powerful and widely used tools, each offering unique features tailored to different use cases—from small businesses to enterprise-scale deployments.
1. Nagios XI – The Industry Standard
Nagios XI remains one of the most trusted names in system monitoring. Known for its robustness and flexibility, it supports monitoring across physical, virtual, and cloud environments. Its plugin-based architecture allows for extensive customization.
- Supports thousands of plugins for extended functionality
- Advanced alerting via email, SMS, and mobile apps
- Comprehensive dashboards with drill-down capabilities
For more details, visit the official Nagios XI website.
2. Zabbix – Open Source Powerhouse
Zabbix stands out as a fully open-source system monitor with enterprise-grade features. It offers real-time monitoring of networks, servers, virtual machines, and cloud services. With built-in automation and AI-driven anomaly detection, Zabbix is ideal for large-scale deployments.
- Auto-discovery of network devices and services
- Support for distributed monitoring across regions
- Highly scalable with support for millions of metrics
Learn more at Zabbix.com.
3. Datadog – Cloud-Native Excellence
Datadog is a SaaS-based system monitor built for modern cloud environments. It integrates seamlessly with AWS, Azure, Google Cloud, Kubernetes, and Docker. Its strength lies in unified observability—combining metrics, logs, and traces in one platform.
- Real-time dashboards with collaborative features
- AI-powered forecasting and anomaly detection
- Extensive API and third-party integrations
Explore Datadog at Datadoghq.com.
4. Prometheus – Ideal for DevOps Teams
Prometheus is a leading open-source system monitor designed for reliability and scalability in dynamic environments. Originally developed at SoundCloud, it’s now a CNCF (Cloud Native Computing Foundation) project and a go-to choice for Kubernetes monitoring.
- Pull-based model with time-series database
- Powerful query language (PromQL)
- Tight integration with Grafana for visualization
Visit Prometheus.io for documentation and downloads.
5. SolarWinds Server & Application Monitor (SAM)
SolarWinds SAM provides deep visibility into both server performance and application health. It’s particularly popular among IT teams managing hybrid environments. The tool excels in automated root cause analysis and performance baselining.
- Pre-built templates for common applications (e.g., SQL, Exchange)
- Customizable alerts and reports
- Integration with Orion platform for network-wide monitoring
Check it out at SolarWinds.com.
6. PRTG Network Monitor – All-in-One Solution
Paessler’s PRTG is a Windows-based system monitor that combines network, server, and application monitoring in a single package. It uses sensors to collect data, making setup intuitive and scalable.
- Auto-discovery of devices and services
- Real-time maps and visualizations
- Support for SNMP, WMI, SSH, and packet sniffing
More info at Paessler.com.
7. New Relic – Full-Stack Observability
New Relic offers a comprehensive system monitor platform that covers infrastructure, applications, and user experiences. Its APM (Application Performance Monitoring) capabilities are among the best in the industry.
- Real-user monitoring (RUM) for frontend performance
- Infrastructure monitoring with auto-host grouping
- Serverless function tracking (AWS Lambda, etc.)
Discover more at NewRelic.com.
Key Metrics Tracked by a System Monitor
To truly understand system health, a system monitor must track a wide array of performance indicators. These metrics provide actionable insights and help prevent outages before they occur.
CPU Usage and Load Average
CPU utilization is one of the most critical metrics. A system monitor tracks how much processing power is being used and whether the system is under sustained load. High CPU usage over time can indicate inefficient code, runaway processes, or insufficient hardware.
- Normal range: 30–70% under typical load
- Load average shows tasks in the run queue over 1, 5, and 15 minutes
- Persistent 90%+ usage may require scaling or optimization
Memory (RAM) Utilization
Memory monitoring helps identify memory leaks and inefficient applications. A system monitor tracks both used and available RAM, as well as swap usage, which indicates when the system is under memory pressure.
- High swap usage often signals insufficient RAM
- Applications consuming excessive memory can be flagged automatically
- Memory pressure can degrade overall system performance
Disk I/O and Storage Health
Disk performance is crucial for databases and file servers. A system monitor tracks read/write speeds, IOPS (Input/Output Operations Per Second), and disk queue length. It also monitors SMART data for early signs of hardware failure.
- High disk latency can bottleneck applications
- Monitoring free space prevents out-of-disk errors
- RAID array health can be integrated into alerts
Network Throughput and Latency
Network performance directly impacts user experience. A system monitor tracks bandwidth usage, packet loss, jitter, and round-trip time (RTT). This is especially important for VoIP, video conferencing, and cloud applications.
- Sudden spikes in traffic may indicate DDoS attacks
- High latency affects real-time applications
- Bandwidth caps can be enforced via monitoring policies
Benefits of Using a System Monitor
Implementing a system monitor brings tangible benefits across technical, operational, and business dimensions. It transforms reactive IT into proactive management.
Prevent Downtime and Outages
One of the primary advantages of a system monitor is its ability to detect issues before they escalate. For example, if disk space drops below 10%, an alert can trigger automated cleanup or notify the admin—preventing a full system crash.
- Proactive alerts reduce mean time to repair (MTTR)
- Threshold-based notifications prevent resource exhaustion
- Historical trends help predict future capacity needs
Improve System Performance
By identifying bottlenecks—such as a slow database query or a memory-hungry process—a system monitor enables targeted optimizations. This leads to faster response times and better user satisfaction.
- Performance baselines help measure improvement
- Resource contention can be resolved through load balancing
- Unused services can be disabled to free up resources
Enhance Security and Compliance
System monitors can detect suspicious activities, such as unauthorized access attempts or unusual process behavior. They also generate audit logs required for compliance with standards like GDPR, HIPAA, and PCI-DSS.
- Log monitoring detects brute-force attacks
- File integrity monitoring (FIM) tracks changes to critical system files
- Automated reporting simplifies compliance audits
How to Choose the Right System Monitor
Selecting the best system monitor depends on your environment, budget, and technical requirements. Here’s a structured approach to making the right choice.
Assess Your Environment
Start by mapping your infrastructure. Are you running on-premises servers, cloud instances, containers, or a hybrid setup? Some tools specialize in cloud environments (like Datadog), while others excel in on-premise networks (like PRTG).
- Cloud-heavy environments benefit from SaaS monitors
- Legacy systems may require agent-based monitoring
- Containerized apps need Kubernetes-aware tools like Prometheus
Define Monitoring Goals
Ask yourself: What do you want to achieve? Is it uptime assurance, performance tuning, security compliance, or cost optimization? Your goals will dictate which features are most important.
- Uptime focus: Prioritize alerting and incident management
- Performance focus: Look for deep application insights
- Security focus: Choose tools with log analysis and FIM
Evaluate Scalability and Integration
A good system monitor should grow with your organization. Check if it supports distributed monitoring, API access, and integration with existing tools like Slack, Jira, or ITSM platforms.
- APIs enable automation and custom dashboards
- Webhooks allow integration with incident response systems
- Plugin ecosystems extend functionality
Setting Up a System Monitor: Step-by-Step Guide
Deploying a system monitor doesn’t have to be complex. Follow this step-by-step process to ensure a smooth implementation.
Step 1: Install the Monitoring Agent or Server
Most system monitors require either a central server or lightweight agents installed on target machines. For example, Zabbix uses a server-agent model, while Datadog deploys a single agent package.
- Download the appropriate package from the vendor
- Install using package managers (apt, yum) or installers
- Ensure firewall rules allow communication
Step 2: Configure Data Collection
Define what metrics to collect and how frequently. Over-monitoring can strain systems, while under-monitoring defeats the purpose. Start with essential metrics: CPU, memory, disk, and network.
- Set polling intervals (e.g., every 30 seconds)
- Enable auto-discovery to find devices automatically
- Customize sensors or plugins for specific needs
Step 3: Set Up Alerts and Notifications
Configure thresholds and notification channels. For example, send an email if CPU exceeds 90% for more than 5 minutes. Use escalation policies for critical alerts.
- Use multiple channels: email, SMS, Slack, PagerDuty
- Define alert severity levels (warning, critical)
- Avoid alert fatigue with deduplication and throttling
Step 4: Create Dashboards and Reports
Visualize data using dashboards. Most tools offer drag-and-drop interfaces. Build views for different stakeholders—IT admins, managers, executives.
- Executive dashboards: High-level uptime and SLA metrics
- Technical dashboards: Detailed performance graphs
- Schedule weekly reports for review meetings
Common Challenges in System Monitoring and How to Overcome Them
Even with the best tools, teams face common pitfalls. Understanding these challenges helps you avoid them and get the most out of your system monitor.
Alert Fatigue
Too many alerts lead to desensitization. Teams may ignore critical warnings because they’re buried in noise. To combat this, implement smart alerting: use thresholds, deduplication, and alert grouping.
- Use dynamic thresholds based on historical data
- Suppress non-critical alerts during maintenance windows
- Route alerts to the right team using on-call schedules
Data Overload
Collecting too much data can overwhelm storage and make analysis difficult. Focus on collecting high-value metrics and use data retention policies.
- Keep raw data for 7–30 days, then aggregate
- Use tiered storage (hot, warm, cold) for cost efficiency
- Leverage AI to highlight anomalies instead of reviewing all data
Lack of Expertise
Many organizations lack staff trained in interpreting monitoring data. Invest in training or choose user-friendly tools with built-in guidance.
- Use tools with AI-assisted diagnostics (e.g., Datadog)
- Provide internal workshops on interpreting dashboards
- Leverage vendor support and documentation
Future Trends in System Monitoring
The field of system monitoring is evolving rapidly, driven by AI, cloud computing, and the rise of edge devices. Staying ahead of these trends ensures your monitoring strategy remains effective.
AI-Powered Anomaly Detection
Modern system monitors are integrating machine learning to detect unusual patterns without predefined thresholds. This reduces false positives and identifies subtle issues before they escalate.
- Adaptive baselines learn normal behavior over time
- Anomaly scores highlight deviations
- Self-healing systems can trigger automated responses
Observability Beyond Monitoring
Observability goes beyond traditional monitoring by combining metrics, logs, and traces to answer *why* something happened. Tools like New Relic and Datadog are leading this shift.
- Tracing helps debug microservices interactions
- Log correlation reduces mean time to resolution
- Context-rich alerts improve troubleshooting
Edge and IoT Monitoring
As more devices operate at the network edge, monitoring must extend beyond data centers. Lightweight agents and MQTT protocols enable real-time tracking of IoT devices.
- Low-bandwidth monitoring for remote sensors
- Local processing reduces latency and bandwidth use
- Centralized dashboards aggregate edge data
What is a system monitor used for?
A system monitor is used to track the performance, availability, and health of computer systems, servers, networks, and applications. It helps detect issues early, prevent downtime, optimize resources, and ensure security and compliance.
Which system monitor is best for small businesses?
For small businesses, PRTG Network Monitor and Zabbix offer excellent value. PRTG has a free version with up to 100 sensors, while Zabbix is fully open-source and highly customizable without licensing costs.
Can a system monitor work in the cloud?
Yes, most modern system monitors like Datadog, New Relic, and Prometheus support cloud environments. They integrate with AWS, Azure, Google Cloud, and Kubernetes to provide real-time visibility across hybrid and multi-cloud infrastructures.
How do I set up alerts in a system monitor?
To set up alerts, define thresholds (e.g., CPU > 90%), choose notification channels (email, SMS, Slack), and configure escalation policies. Most tools offer web interfaces to manage alert rules and test notifications.
Is system monitoring the same as observability?
Not exactly. System monitoring focuses on collecting and alerting based on predefined metrics. Observability goes further by enabling deep exploration of system behavior using logs, metrics, and traces to understand *why* issues occur.
Choosing the right system monitor is a strategic decision that impacts uptime, performance, and security. From open-source solutions like Zabbix and Prometheus to enterprise platforms like Datadog and New Relic, the options are vast. The key is aligning your choice with your infrastructure, goals, and team expertise. As technology evolves, so too must monitoring practices—embracing AI, automation, and full-stack observability will define the future of IT operations. Whether you’re managing a single server or a global cloud network, a robust system monitor is your first line of defense and your best tool for optimization.
Further Reading: